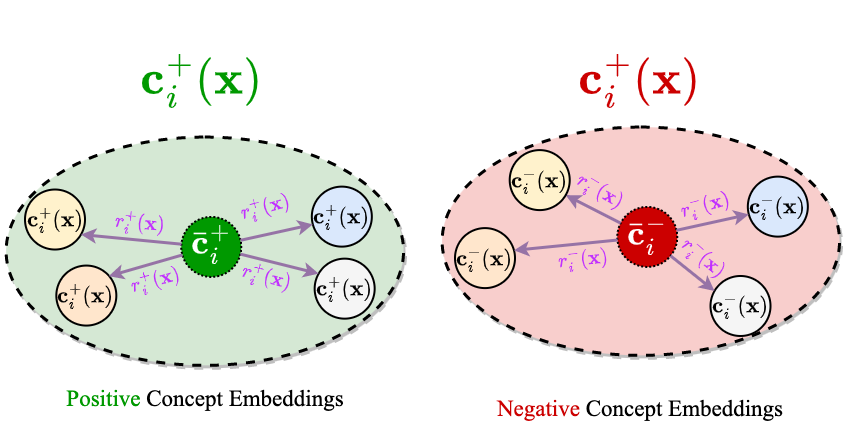
Avoiding Leakage Poisoning: Concept Interventions Under Distribution Shifts
We show that concept leakage can lead to faulty interventions in out-of-distribution settings. Then, we introduce a new representation decomposition to prevent this.

Welcome to my humble abode! I am a Junior Research Fellow (JRF) in Computer Science at Trinity College, Oxford. I also hold research positions at the University of Oxford (Associate Research Fellow) and the University of Cambridge (Visiting Researcher). My research lies within the general field of Artificial Intelligence (AI), where I am roughly interested in interpretability (e.g., explaining a model using human-like concepts), representation learning (e.g., how can one manipulate concept representations to influence or steer model behavior), and human-AI collaboration (e.g., test-time feedback and interventions). To find out more about my research, please see my research page.
If you would like to collaborate or chat, feel free to send me an email. I am always happy to connect!
We show that concept leakage can lead to faulty interventions in out-of-distribution settings. Then, we introduce a new representation decomposition to prevent this.
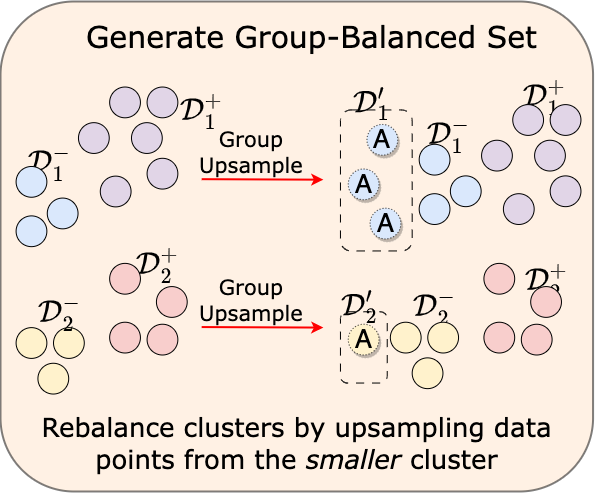
We show that model selection for existing unsupervised bias mitigation methods is prone to yielding biased models unless privileged information (e.g., group labels) is available. To address this, we propose a simple mechanism to mitigate biases that requires no model selection or privileged information.
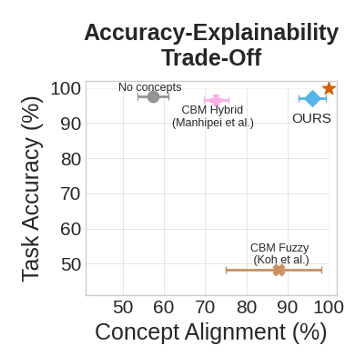
We introduce concept embeddings to construct accurate deep neural networks that are both interpretable and intervenable, even when concept supervision is incomplete.
Lucky to have three accepted papers at ICML 2026! One position paper challenging a common characterization of information leakage [1], and two main track papers led by an amazing set of colaborators (one of which was accepted as an spotlight) [2, 3].
I will be giving an invited talk at ICLR 2026's Unifying Concept Representation Learning Workshop!
We started a new journal club on interpretable AI. Everyone is more than welcomed to join!
Our paper on hierarchical concept discovery was accepted at ICLR 2026!
I passed my PhD defense (viva voce) without corrections.
I started a Junior Research Fellowship (JRF) in Computer Science at Trinity College, Oxford.
Pietro Barbiero and I gave a talk on Foundations of Interpretable Models at the Neuro-Symbolic AI Summer School based on this paper.
I co-presented a tutorial on Concept-based Interpretable Deep Learning at AAAI 2025.
Our Causal Concept Graph Models work was accepted at ICLR 2025.
Our work on unsupervised bias mitigation was accepted at ECCV 2024 as an oral and nominated for Best Paper.
One paper was accepted at ICML 2024 where I also co-organized the LatinX in AI workshop.
Our IntCEM paper was accepted at NeurIPS 2023 as a spotlight.
Our Concept Embedding Model paper was accepted at NeurIPS 2022.
I completed my MEng in Computer Science from Cornell University with the highest GPA in my cohort.
A tiny bit of light on Kolmogorov Complexity and the incompressibility method.
Welcome to my blog! Here is something weird for you…